AI 基础认知
一、AI 三层架构
按照 AI 应用 → 模型服务 → Raw Model 三层,层级由上到下:
| 层级 | 说明 | 示例 |
|---|---|---|
| AI 应用 | 面向用户的产品与工具 | Agent、Claude Code、Codex |
| 模型服务 | 包装原生模型的 API 层 | OpenAI API、temperature、top_k、top_p |
| Raw Model | 裸模型 / 原生模型 | GPT、Claude、Gemini、DeepSeek 等 |
二、原生模型(Raw Model)工作原理
模型的本质可以理解为一个 函数:给输入,经过函数加工,给出输出。
在模型内部是经过一系列复杂计算,本质上不具有感情。
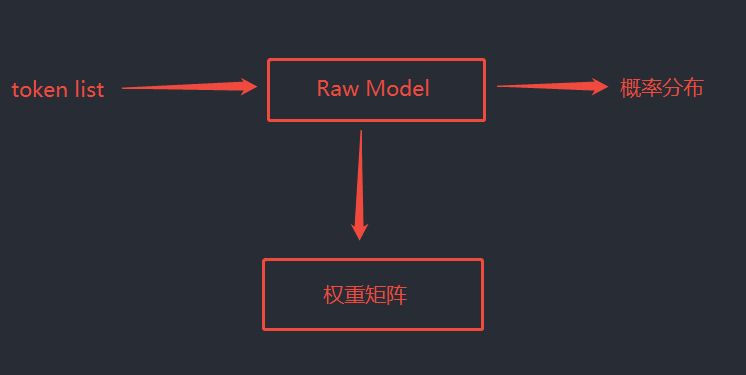
工作流程
自然语言输入 → Token 化 → 原生模型计算 → 概率分布 → 自然语言输出① Token List(分词)
将自然语言翻译为原生模型能理解的 token 序列:
输入:你好,很高兴认识你。
输出:[1, 5, 6, 99, 20, ...]② 原生模型计算
将 token 序列送入权重矩阵,逐个计算 下一个 token 的概率值。
③ 概率分布
由后续处理流程将概率分布转换为自然语言输出。
三、模型服务(Model Service)
3.1 模型服务大致流程
模型服务是对原生模型进行包装的一层,提供额外功能和接口。目前常见模型服务商有 OpenAI、Anthropic 等。
OpenAI 或许不是最强的,但因为历史原因,大家尊重它的历史地位,所以 SDK 大都以 OpenAI 为标准。
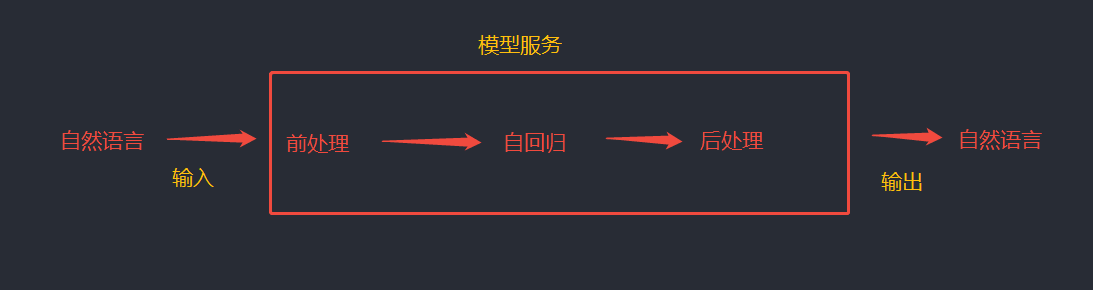
模型服务内部三步骤:
① 前处理
主要进行身份验证、API-Key 校验、提示词注入。
LLM 本身可识别 system 和 user 的提示词。但服务商通常会在这一步 注入自己的提示词 再发给大模型。
举例:
user: 你好,你是什么模型?
模型服务商:
- 微调 system:'如果用户问你是哪个模型,你就说你是 Claude'
- 校验 API-Key(盈利使用)
- 将微调过的提示词发送给原生模型② 自调用(核心步骤)
模型算力消耗主要发生在此步骤。用伪代码模拟:
function selfCall(input) {
const input = [];
const output = [];
while (1) {
const prob = rawModel(input); // 交由 rawModel 计算出概率分布
const token = pickToken(prob); // 从概率分布中选取一个 token
if (isOver) break;
output.push(token); // 记录输出
input.push(token); // 将该次输出重新打入输入,继续循环
}
}最终流程示意:
"你好,你是哪个模型?"
↓ 自调用
"你好,你是哪个模型?我"
↓ 自调用
"你好,你是哪个模型?我是"
↓ 自调用(循环...)
"你好,你是哪个模型?我是 Claude。"由此可见,算力消耗就在这一步 —— 每生成一个 token 都需要将新的序列重新输入模型计算。
③ 后处理
主要进行 安全校验(内容合规、合法性检查等),然后输出。 不同服务商校验力度不同 —— Grok 在这方面校验就比较宽松。
3.2 Temperature(模型温度)
使用 OpenAI SDK 时常见的参数,取值范围一般为 0 ~ 2。
| 温度值 | 效果 | 适用场景 |
|---|---|---|
| 低(接近 0) | 输出更一致、更精确,概率发散空间小 | 代码生成、数学推理 |
| 高(接近 2) | 输出更随机、更富创造性 | 创意写作、头脑风暴 |
一般建议设置为 0.7 左右。
3.3 Top_k
假设 Top_k = 10:
在 raw 模型生成的概率分布中,只取概率排名前 10 的 token 作为候选。
3.4 Top_p(核采样)
假设 Top_p = 0.8(即 80%):
将 token 按概率从高到低排序,依次累加,累加到 80% 为止,只取前面这几个 token。
token1: 70% ─┐
token2: 5% ├── 累加到 80%,只取这 3 个
token3: 5% ─┘
token4: 3% ← 不取
...四、AI 编程核心关注点
AI 当前还处于发展期,很多东西没有标准。就连 OpenAI 的 SDK 都只是 行为规范,靠大家默认遵守。层出不穷的新概念,有的生命周期只能按周计算。
核心永远不变:给 Raw Model 输入了什么,Raw Model 输出了什么。 变的都是应用层,抛开细枝末节,把控核心即可。
4.1 拦截代理
当前应用流程:
用户输入 → 模型服务商 DeepSeek(Skill)→ 模型服务(Raw Model)在流程中间加入个人代理服务器来拦截:
用户输入 → 模型服务商 DeepSeek(Skill)→ 个人代理服务器 → 模型服务(Raw Model)代理服务器的价值:拦截模型请求,记录监控日志,洞察模型服务商到底在发什么。
使用步骤
Step 1 — 修改 .env 文件
# 代理服务器环境变量配置
# 必需:目标服务器地址
TARGET_URL=https://api.deepseek.com # 换成你自己的模型服务
# 可选:代理服务器监听端口(默认:3000)
PORT=3000
# 可选:日志目录(默认:./logs)
LOG_DIR=./logs
# 可选:日志级别(error / warn / info / debug,默认:info)
LOG_LEVEL=infoStep 2 — 安装依赖并启动
npm install
npm startStep 3 — 修改 AI 工具的转发地址
以 Cursor 和 Trae 为例(Codex、Claude CLI 请自行查询):
- 下载新版 IDE
- 打开 AI IDE → 自定义模型 → 自定义配置
- 修改请求地址为
http://localhost:3000
Step 4 — 发送一条请求
在客户端向任意模型发送:你好,你是什么模型
回到代理服务器打开日志文件,可以看到拦截日志:
转发目标:https://api.deepseek.com/chat/completions
请求日志
时间:2026-05-16T01:53:13.608Z
请求ID:k2zgb2tanf
耗时:3219ms
请求头:
// xxxx ...Step 5 — 查看请求体
把请求体复制出来,可以看到 DeepSeek 在发出用户提示的同时,自己加上了系统的 Skill:
{
"type": "function",
"function": {
"name": "Skill",
"description": "Execute a skill within the main conversation...",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The skill name (no arguments). E.g., \"pdf\" or \"xlsx\""
}
},
"required": ["name"],
"additionalProperties": false
}
}
}(实际 Skill prompt 内容更长,此处省略完整细节)
4.2 模型服务商 Skill 调用流程
Skill 的本质就是一段 Prompt。
整个模型服务商的实际流程:
用户提示词
↓
DeepSeek(带上自己的 Skill)
↓
Raw Model(发现需要调用 Skill,返回请求给 DeepSeek)
↓
DeepSeek 接收请求,发送详细 Skill 给 Raw Model
↓
Raw Model 返回输出给 DeepSeek
↓
用户结语:以后任何新概念的拆解分析,都可以沿用这个思路 —— 追踪「给 Raw Model 输入了什么」和「Raw Model 输出了什么」。