webpack 编译过程
[TOC]
webpack 的作用是将源代码编译(构建、打包)成最终代码
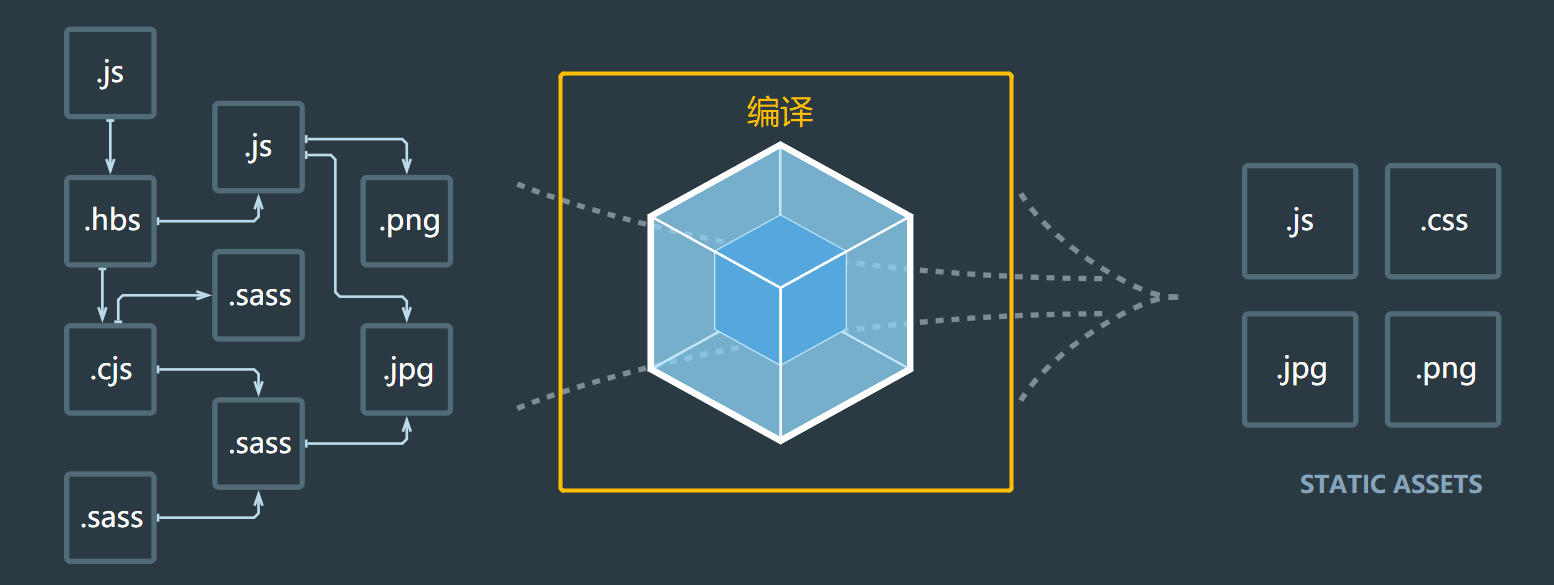
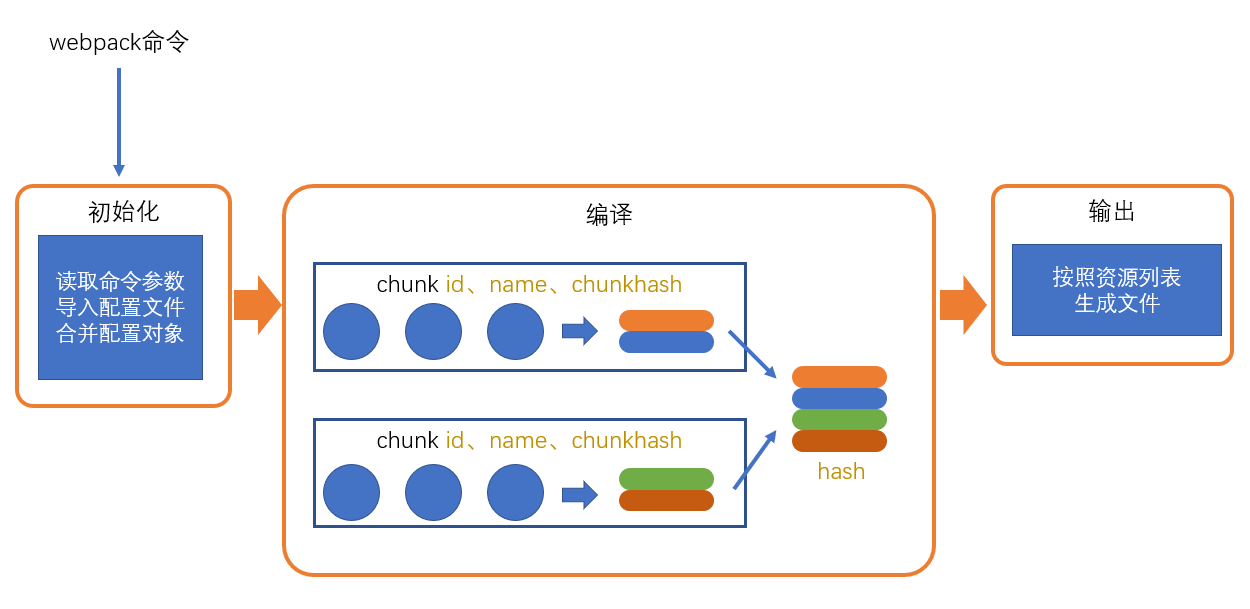
整个过程大致分为三个步骤
- 初始化
- 编译
- 输出

初始化
此阶段,webpack 会将CLI 参数、配置文件、默认配置进行融合,形成一个最终的配置对象。
对配置的处理过程是依托一个第三方库yargs完成的
此阶段相对比较简单,主要是为接下来的编译阶段做必要的准备
目前,可以简单的理解为,初始化阶段主要用于产生一个最终的配置
编译
- 创建 chunk
chunk 是 webpack 在内部构建过程中的一个概念,译为块,它表示通过某个入口找到的所有依赖的统称。
根据入口模块(默认为./src/index.js)创建一个 chunk,每一个 chunk 最终都会说生成一个 js 文件
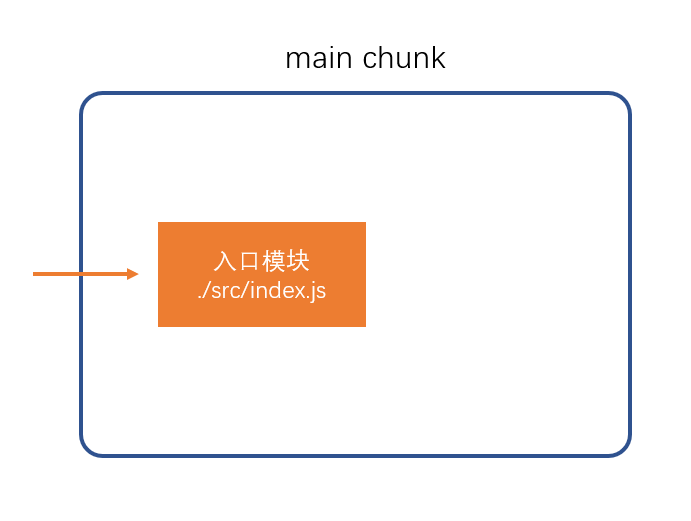
每个 chunk 都有至少两个属性:
- name:默认为 main
- id:唯一编号,开发环境和 name 相同,生产环境是一个数字,从 0 开始
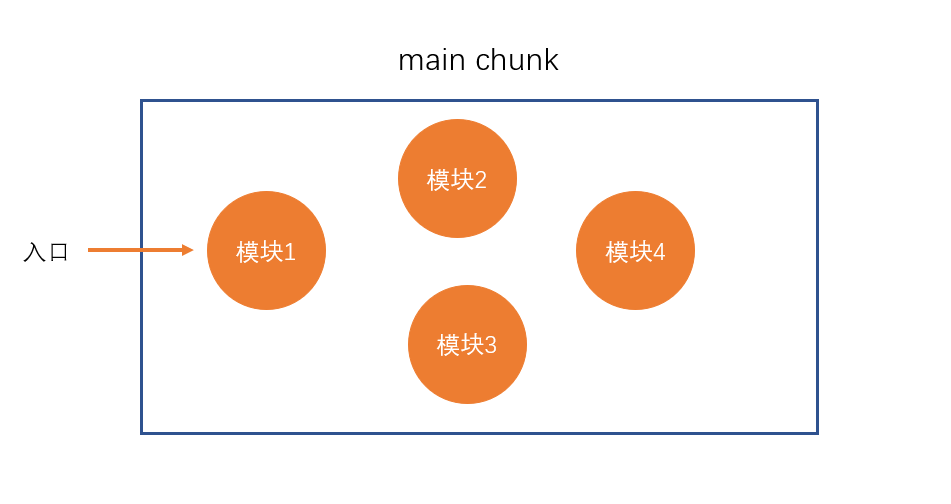
- 构建所有依赖模块
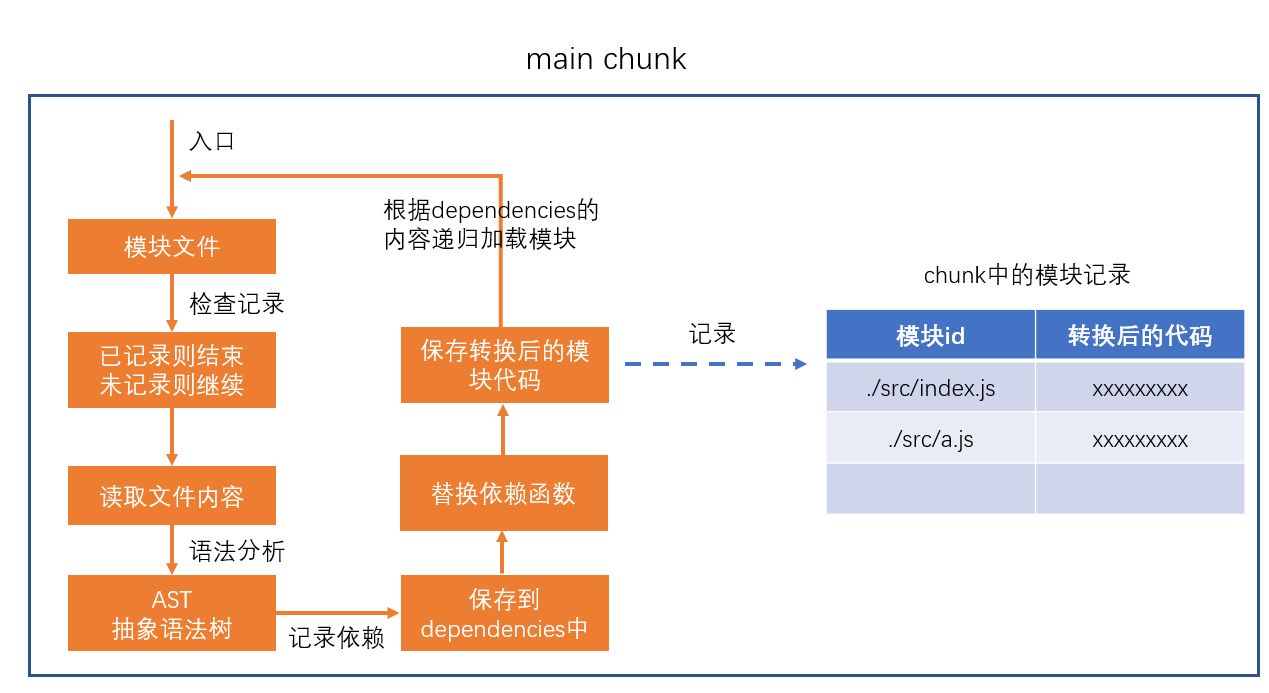
AST 在线测试工具:https://astexplorer.net/
main chunk 执行分析:
js
//index.js
require("./a");
require("./b");
console.log("我是index module");
//a.js
require("./b");
console.log("我是module a");
module.exports = "a";
//b.js
console.log("我是module b");
module.exports = "b";
构建过程(对照上面图片流程)
/*
index.js (未加载)
读取文件内容,并进行AST语法分析
dependencies:['./src/a.js','./src/b.js']
替换依赖函数,保存转换后的模块代码
递归加载a.js
a.js (未加载)
- AST
- dependencies:['./src/b.js']
- 替换依赖函数,保存转换后的模块代码
- 递归加载b.js
b.js (未加载)
- AST
- dependencies:[]
- 替换依赖函数,保存转换后的模块代码
- 检测到b没有依赖
此时,继续循环index的dependencies,继续加载b.js(对照模块记录表格)
b.js(已加载) -- 退出递归
*/
生成的模块记录表格:
/*
保存的模块记录
模块id 转换后的代码(字符串)
./src/index.js `_webpack_require("./a");
console.log("我是index module");`
./src/a.js `_webpack_require("./b");
console.log("我是module a");`
./src/b.js `console.log("我是module b");`
*/简图
- 产生 chunk assets
在第二步完成后,chunk 中会产生一个模块列表,列表中包含了模块 id和模块转换后的代码
接下来,webpack 会根据配置为 chunk 生成一个资源列表,即chunk assets,资源列表可以理解为是生成到最终文件的文件名和文件内容
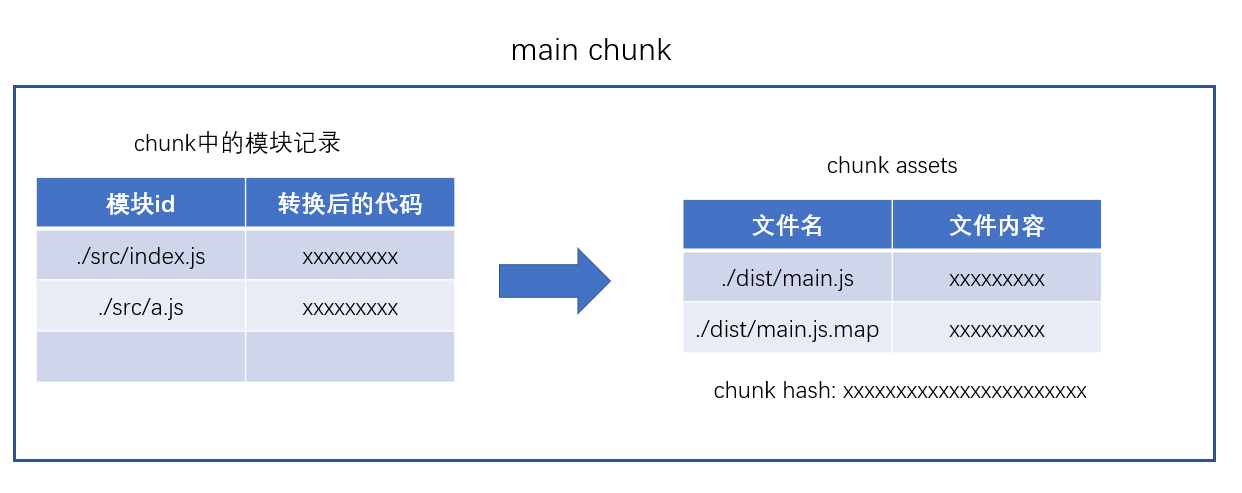
chunk hash 是根据所有 chunk assets 的内容生成的一个 hash 字符串 hash:一种算法,具体有很多分类,特点是将一个任意长度的字符串转换为一个固定长度的字符串,而且可以保证原始内容不变,产生的 hash 字符串就不变
简图
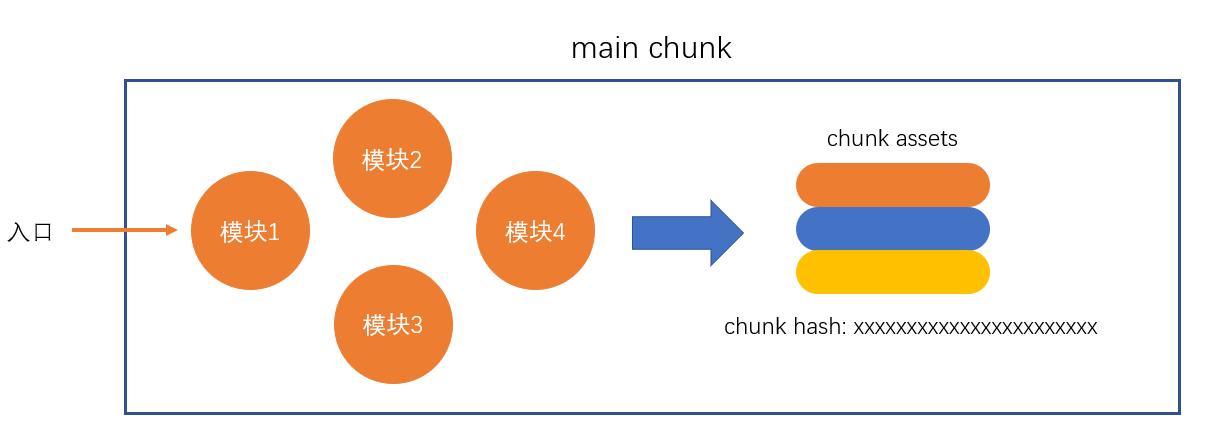
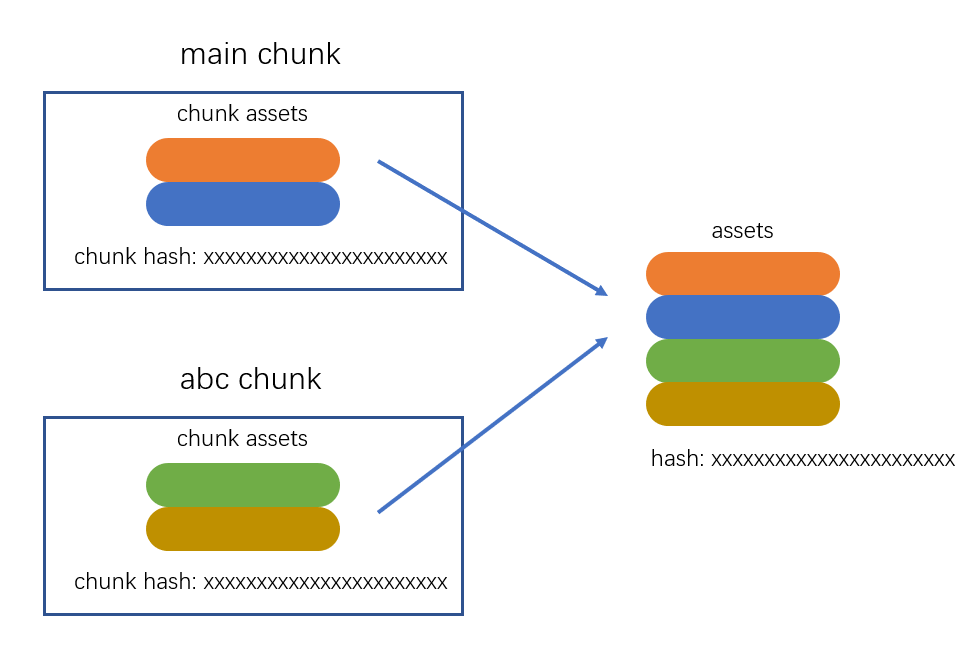
- 合并 chunk assets
将多个 chunk 的 assets 合并到一起,并产生一个总的 hash
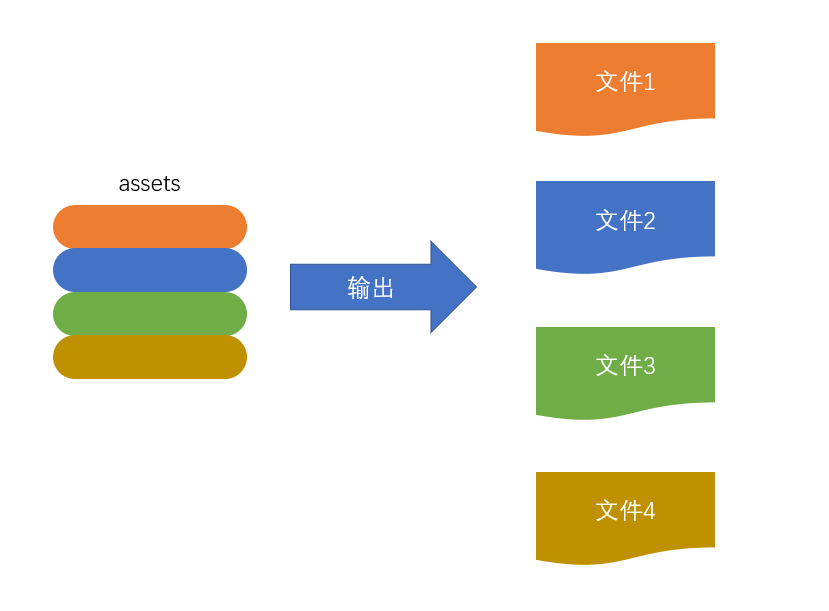
输出
此步骤非常简单,webpack 将利用 node 中的 fs 模块(文件处理模块),根据编译产生的总的 assets,生成相应的文件。
总过程
涉及术语
- module:模块,分割的代码单元,webpack 中的模块可以是任何内容的文件,不仅限于 JS
- chunk:webpack 内部构建模块的块,一个 chunk 中包含多个模块,这些模块是从入口模块通过依赖分析得来的
- bundle:chunk 构建好模块后会生成 chunk 的资源清单,清单中的每一项就是一个 bundle,可以认为 bundle 就是最终生成的文件
- hash:最终的资源清单所有内容联合生成的 hash 值
- chunkhash:chunk 生成的资源清单内容联合生成的 hash 值
- chunkname:chunk 的名称,如果没有配置则使用 main
- id:通常指 chunk 的唯一编号,如果在开发环境下构建,和 chunkname 相同;如果是生产环境下构建,则使用一个从 0 开始的数字进行编号
总过程梳理
js
/*
webpack编译过程梳理:
- 初始化
- 编译
- 输出
一、初始化
- 将命令行、配置文件(webpack.config.js)、默认配置整合,形成最终的配置对象
二、编译阶段
1.创建chunk
- chunk: 当index.js-->a.js-->b.js(index依赖a.js依赖b.js),这样文件就构成一个chunk。
- chunk可以有多个的,每个chunk是有自己的名字和id。
名字:默认为main
id:唯一编号,开发环境和name相同,生产环境从0开始编号
2.构建所有的依赖模块
-目的:为了生成模块记录表格,方便后续的模块加载。
-表格格式:
模块id 转换后的代码(字符串)
./src/index.js ·xxxxxxxxxxxxx·
./src/a.js ·xxxxxxxxxxxxx·
...其它模块(依赖) ·xxxxxxxxxxxxx·
3.产生chunk assets
- 根据第二步的模块记录表格,为chunk生成chunk assets(资源列表)
- 资源列表chunk assets: 可以理解为是生成到最终文件的文件名和文件内容
- 资源列表
文件名 文件内容
./dist/main.js ·xxxxxxxxxxxxx·
./dist/main.js.mao ·xxxxxxxxxxxxx·
-- chunk hash:xxxxxxxxxxxxxxxx --
-chunk hash:是根据所有chunk assets的内容生成的一个hash字符串
- 根据这个资源列表,去生成dist文件夹下的文件,将内容写入到文件中。
4.合并chunk assets
将多个的chunk assets合并成一起,产生一个总的hash
三、输出
webpack将利用node中的fs模块(文件处理模块),根据编译产生的总的assets,生成相应的文件。
*/